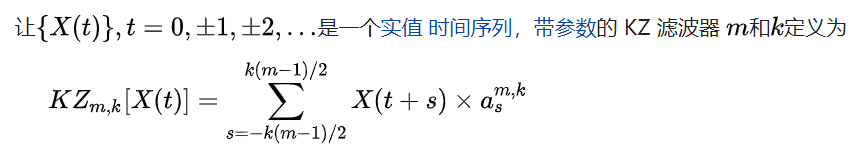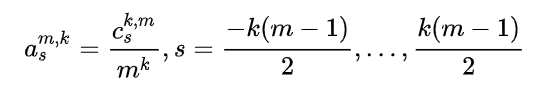defkz_filter(data, m, k): """首先看一下参数的使用,分别代表了什么 : data 这里的data是一个集合,是一个大小为N的一阶随机数集合,数据丢失就用“”空字符串代替,确保长度对上 : m m是一个滤波器的长度(移动平均窗口的长度) : k k是移动平均窗口的迭代次数 : 返回值 返回值是一个元素数量为N-k*(m-1)的集合 之后我们会给定一个时间序列集合data 这个集合是可以自己去声明的,一个随机序列,后面我们再去赋值测试 """
coef = _kz_coeffs(m, k) data = _kz_prod(data, coef, m, k)
ef _kz_coeffs(m, k): """ :会返回一个长度为`k*(m-1)+1`的集合结果 这是一个可以直接调用的功能函数不用深究,会用就行 """
# Coefficients at degree one coef = np.ones(m)
# Iterate k-1 times over coefficients for i inrange(1, k): # np.zeros()函数返回一个元素全为0且给定形状和类型的数组 t = np.zeros((m, m+i*(m-1))) for km inrange(m): t[km, km:km+coef.size] = coef
coef = np.sum(t, axis=0)
assert coef.size == k*(m-1)+1
print(coef/m**k) return coef/m**k
再然后是根据给定时间序列T进行下一步运算
1 2 3 4 5 6 7 8 9 10 11 12 13
def_kz_prod(data, coef, m, k, t=None):
n = data.size #调用了sliding_window函数,后面详解 data = sliding_window(data, k*(m-1)+1) assert data.shape == (n-k*(m-1), len(coef))
# Restrict KZ product calculation to provided indices if t isnotNone: data = data[t] assert data.shape == (len(t), len(coef))
return data*coef
接上一步看看sliding_window函数用法
1 2 3 4 5 6 7 8 9 10 11 12
defsliding_window(arr, window): """未来在numpy阵列上生成滑动窗口,其实也不用管太多 :arr 这里是传进来的时间轴序列 :window 这里是窗口长度,也就是遍历的长度k*(m-1)+1 :return: A :class:`numpy.ndarray` of shape `(n1, ..., nN-window+1, window)`. """